首页
技术小册
AIGC
面试刷题
技术文章
MAGENTO
云计算
视频课程
源码下载
PDF书籍
「涨薪秘籍」
登录
注册
并发编程线程基础
并发编程的其他基础知识
Java并发包中的ThreadLocalRandom类原理剖析
Java并发包中原子操作类原理剖析
Java并发包中并发List源码剖析
Java并发包中锁原理剖析
Java并发包中并发队列原理剖析
Java并发包中线程池ThreadPoolExecutor原理探究
Java并发包中ScheduledThreadPoolExecutor原理探究
Java并发包中线程同步器原理剖析
当前位置:
首页>>
技术小册>>
Java并发编程
小册名称:Java并发编程
## 并行与并发区别 并发指同一**时间段**多个任务同时都在进行,并且都没有执行结束,而并行是说在**单位时间**内多个任务在同时运行。 并发任务强调在一个时间段内同时进行,而一个时间段有多个单位i时间构成,所以说并发的多个任务在单位时间内不一定同时在执行。 一个CPU同时只能执行一个任务,所以单CPU时代多个任务都是并发执行的。 > 注:在多线程时间中,线程的个数往往多于CPU个数,所以即使存在并行任务,一般还是称为多线程并发编程而非多线程并行编程。 ## Java中的线程安全问题 示例:计数器问题 | | t1 | t2 | t3 | t4 | | ----- | --------------------------- | --------------------------- | --------------------- | ---------- | | 线程A | 从主内存读取count值到本线程 | 递增本地线程count的值 | 写回主内存 | | | 线程B | | 从主内存读取count值到本线程 | 递增本地线程count的值 | 写回主内存 | 假设count初始值为0,线程A在t1和t2时间读取了主内存中的count并在本地将其递增为1,t2时线程B从主内存中读取了count的值0并于t3时将其递增为1,t3时线程A将count的新值1更新到主内存,t4时线程B进行了同样的操作,最终主内存中count的值为1而非我们想要的2。 ## Java中共享变量的内存可见性问题 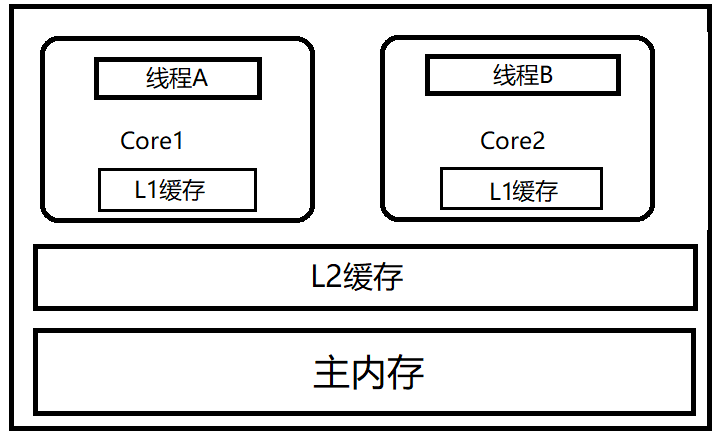 如图是一个双核CPU模型,每个核都有自己的一级缓存,有些架构里还有一个所有CPU共享的二级缓存。 现假设线程A和线程B同时处理一个共享变量,由于Cache的存在,将会出现**内存不可见**问题,原因如下: - 线程A先获取共享变量X的值(假设X=0),由于L1和L2缓存中都没有X的值,线程A会直接从主存中去取X的值并将其缓存到L1和L2中。然后A将X的值递增为1,将其写入缓存L1和L2,并刷新到主存。 - 线程B也要获取X的值,由于Core2中1级缓存没有X的值,B会从L2缓存取到X的值1。然后B修改X为2,将其更新至L1、L2和主存。 - 线程A又需要获取X的值,发现L1中已经有了,但此时A获得的X=1,与主存中X=2不同了! ## synchronized关键字 synchronized关键字是一种原子性内置锁,线程进入synchronized代码块前会自动获取监视器锁,这时其他线程再访问该同步代码块是会被阻塞挂起。 前面的共享变量内存可见性问题主要是线程的工作内存导致的,而synchronized的内存语义可以解决此问题。 synchronized的内存语义: - 进入synchronized块:把synchronized块中使用到的变量从线程的工作内存中清除,这样当synchronized块中要使用该变量时,就会从主存中去取。 - 离开synchronized块:把synchronized块中对共享变量的修改刷新到主内存。 ### 示例 ```java public class ThreadSafeInteger { private int value; public synchronized int get() { return value; } public synchronized void set(int value) { this.value = value; } } ``` > 注1:get()方法虽然只是读操作,但仍要加上synchronized来实现value的内存可见性。 > > 注2:使用synchronized虽然解决了共享变量value的内存可见性问题,但由于synchronized是独占锁,同时只能有一个线程调用get()方法,其他调用线程则会被阻塞,同时存在线程切换、调度的开销,效率并不高。 ## volatile关键字 当一个变量声明为volatile时,线程在写入变量时就不会把值缓存,而是直接把值刷新到主存中;当其他线程读取该变量时,会从主存中重新获得最新值,而不是使用当前工作内存中的值。 ### 示例 ```java public class ThreadSafeInteger { private volatile int value; public int get() { return value; } public void set(int value) { this.value = value; } } ``` > 注:volatile虽然保证了可见性,但并不保证操作的原子性。 ### volatile不保证原子性示例 ```java public class Test { private static volatile long _longVal = 0; public static void main(String[] args) { Thread t1 = new Thread(new LoopVolatile1()); t1.start(); Thread t2 = new Thread(new LoopVolatile2()); t2.start(); try{ t1.join(); t2.join(); }catch(Exception e){ e.printStackTrace(); } System.out.println("final val is: " + _longVal); } private static class LoopVolatile1 implements Runnable { public void run() { long val = 0; while (val < 100000) { _longVal++; val++; } } } private static class LoopVolatile2 implements Runnable { public void run() { long val = 0; while (val < 100000) { _longVal++; val++; } } } } ``` 运行上述代码,发现每次输出不同。 ### 使用场景 - 写入变量值不依赖当前值。如果依赖当前值,将是获取-计算-写入三步,这三步并非原子性,volatile也不保证原子性。 - 读写变量值时没有加锁。因为加锁本身已经保证了内存可见性,再使用volatile就是画蛇添足。 ## Java中的CAS操作 CAS即Compare And Swap,JDK中Unsafe类提供了一系列的compareAndSwap*方法。 ### 示例 下面以compareAndSwapLong(Object obj, long valueOffset, long expect, long update)方法为例进行介绍 boolean compareAndSwapLong(Object obj, long valueOffset, long expect, long update)方法:如果obj对象中内存偏移值为valueOffset的变量值为expect,则使用新的值update替换之。这是处理器提供的一个原子性指令。 ### ABA问题 #### 问题描述 假如线程A要去通过CAS修改变量X,要先判断X当前值是否改变过,如果“未改变”,则更新之。但这并不能保证X没有被改变过:假如A修改X前,线程B修改了X的值,然后又修改回来,A的CAS操作仍能成功,但X实际上发生过改变。 #### 解决方案 JDK中的AtomicStampedReference类给每个变量都配备了一个时间戳,从而避免了ABA问题的产生。 ## Unsafe类 JDK的rt.jar 包中的UnSafe类提供了硬件级别的原子性操作,Unsafe类中的方法都是native方法,使用JNI的方式访问本地C++实现库。 Unsafe类可以直接操作内存,这是不安全的,如果是普通的调用的话,它会抛出一个SecurityException异常;只有由主类加载器加载的类才能调用这个方法。 见下: ```java public static Unsafe getUnsafe() { Class localClass = Reflection.getCallerClass(); if(!VM.isSystemDomainLoader(localClass.getClassLoader())) { throw new SecurityException("Unsafe"); } else { return theUnsafe; } } ``` 但通过万能的反射,还是可以使用到Unsafe类的: ```java Field f = Unsafe.class.getDeclaredField("theUnsafe"); f.setAccessible(true); Unsafe unsafe = (Unsafe) f.get(null); ``` ## Java指令重排序 Java内存模型允许编译器和处理器对**不存在数据依赖性的指令**进行重排序以提高性能。 如下: ```java int a = 1; //(1) int b = 2; //(2) int c = a + b; //(3) ``` 如果有必要,JVM完全可以将(2)放在(1)前执行,但这并不会影响最终结果。 单线程下这样做是ok的,但多线程下就会出现问题: ```java private static int num = 0; private static boolean ready = false; public static void main(String[] args){ Thread t1 = new Thread(new ReadTask()); Thread t2 = new Thread(new WriteTask()); t1.start(); t2.start(); try{ Thread.sleep(100); }catch(InterruptedException e) { e.printStackTrace(); } System.out.println("main exit!"); } public static class ReadTask implements Runnable { @Override public void run() { while(true) { if(ready) { System.out.println(num); return; } } } } public static class WriteTask implements Runnable { @Override public void run() { num = 1; //(1) ready = true; //(2) } } ``` 理论上这段代码并不一定输出1,因为进行指令重排序后,WriteTask中的(2)语句有可能会先于(1)执行,导致输出为0。 ## 锁 ### 乐观锁与悲观锁 - 乐观锁:认为数据在一般情况下不会造成冲突,所以在访问记录前不会加排他锁,而是在进行数据提交更新时才会对数据冲突进行检测并返回一定状态。用户需根据状态判断是否更新成功并进行相应操作。 - 悲观锁:对数据被外界修改持保守态度,认为数据很容易被其他线程更改,所以在数据被处理前进行加锁。 ### 公平锁与非公平锁 - 公平锁:线程获取锁的顺序是按照请求锁的时间顺序决定的,先请求先得。 - 非公平锁:不保证先请求的线程先获得锁。 > 注:在没有公平性需求的前提下尽量使用非公平锁,因为公平锁会带来额外性能开销。 ### 独占锁与共享锁 - 独占锁:任何时候都只有一个线程能得到锁,如ReentrantLock。 - 共享锁:可以多个线程持有,如ReadWriteLock读写锁。 ### 可重入锁 一个线程要再次获取自己已经获取了的锁时如果不被阻塞,则该锁为可重入锁。 ```java public class Test{ public synchronized void f1() { System.out.println("f1..."); } public synchronized void f2() { System.out.println("f2..."); f1(); } } ``` 上述代码中,调用f2()并不会造成阻塞,说明synchronized内部锁是可重入锁。 ### 自旋锁 当前线程获取锁时,如果发现锁已经被其他线程占有,并不会马上阻塞自己,而是在不放弃CPU使用权的情况下,多次尝试获取,到一定次数后才放弃。目的是使用CPU时间换取线程阻塞与调度的开销。
上一篇:
并发编程线程基础
下一篇:
Java并发包中的ThreadLocalRandom类原理剖析
该分类下的相关小册推荐:
Java高并发秒杀入门与实战
Java必知必会-Maven高级
Mybatis合辑1-Mybatis基础入门
Mybatis合辑2-Mybatis映射文件
Mybatis合辑3-Mybatis动态SQL
Java语言基础13-类的加载和反射
Spring Cloud微服务项目实战
Java语言基础9-常用API和常见算法
Mybatis合辑4-Mybatis缓存机制
Java语言基础7-Java中的异常
Java面试指南
经典设计模式Java版






