首页
技术小册
AIGC
面试刷题
技术文章
MAGENTO
云计算
视频课程
源码下载
PDF书籍
「涨薪秘籍」
登录
注册
ChatGPT 的前世今生
ChatGPT 的训练流程
ChatGPT 的优势
ChatGPT 应用场景
应用场景:AI客服
应用场景:AI文案
应用场景:AI作图
应用场景:AI写代码
ChatGPT 注册指南(保姆级)
ChatGPT 提问的艺术
ChatGPT 写作
ChatGPT 指令大全
ChatGPT 中文调教指南
当前位置:
首页>>
技术小册>>
ChatGPT使用指南
小册名称:ChatGPT使用指南
由于 ChatGPT 并没有放出论文,我们没法直接了解 ChatGPT 的设计细节。但它的博客中提到,ChatGPT 用的是和 InstructGPT一样的方法,只是在数据收集上和 InstructGPT 不一样 -- ChatGPT 用的是多轮对话作为数据集。 还有 InstructGPT 是在 GPT-3 上做微调,而 ChatGPT 是在 GPT3.5 上做微调。因此我们可以参考 InstructGPT的论文去理解 ChatGPT。 **InstructGPT 的技术原理图** 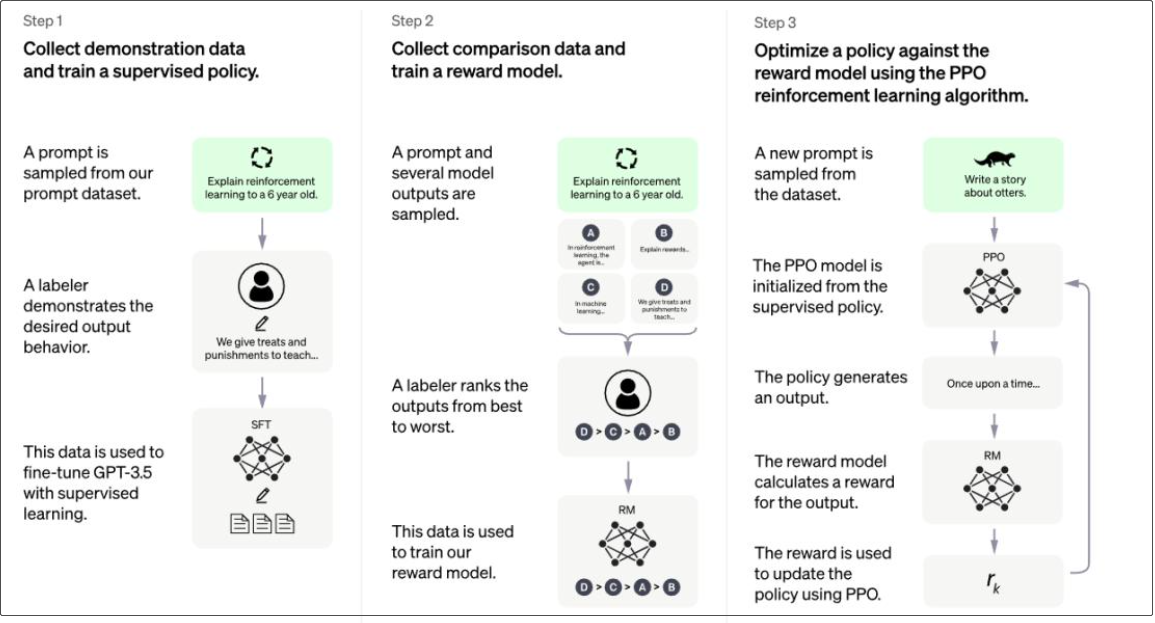 **ChatGPT 博客中的技术原理图** 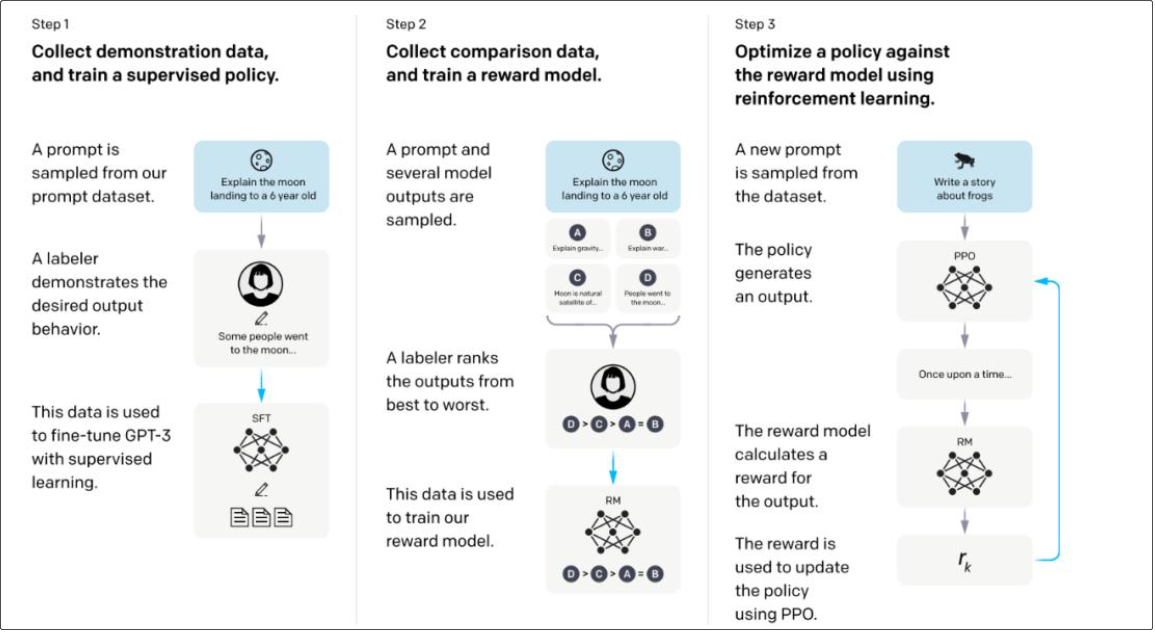 ChatGPT 的训练流程包含三个步骤: 1.监督学习。收集人工编写的期望模型,如何输出的数据集,并使用其来训练一 个生成模型(GPT3.5- based); 简单说,就是根据人编写的答案,训练出一个简单模型,回答会有很大的局限性。 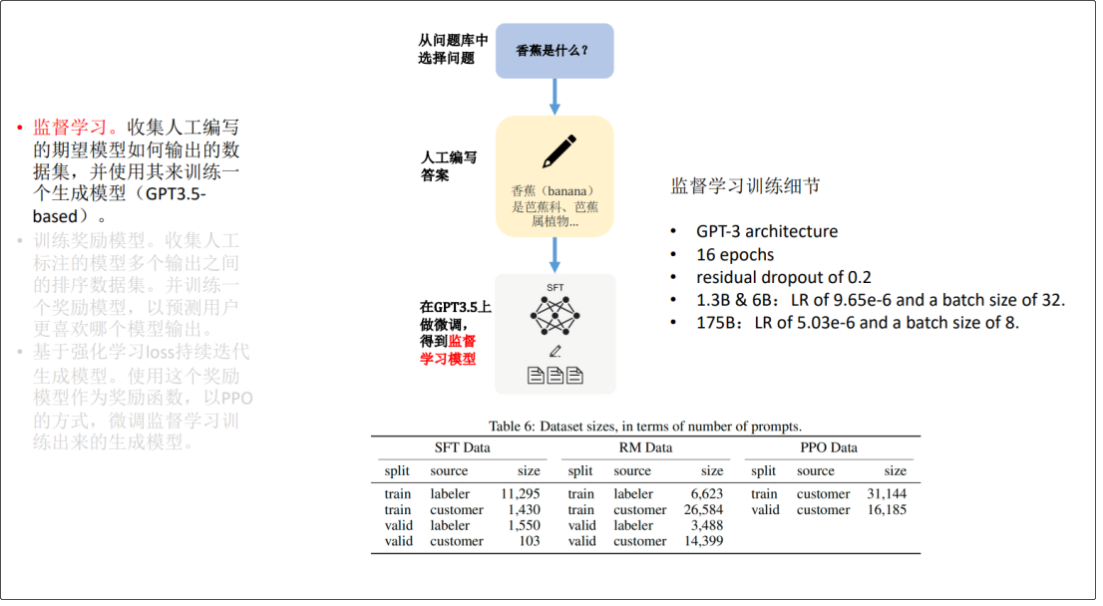 2.训练奖励模型。收集人工标注的模型多个输出之间的排序数据集。并训练一 个奖励模型,以预测用户更喜欢哪个模型输出。 说明:由于第一步训练出来的模型的回答会有很大的局限性,有正向回答,又有负向回答, ChatGPT 不知道给出那个答案更合适,于是通过人工对答案进行排序,再利用排序结果训练出奖励模型(打分) 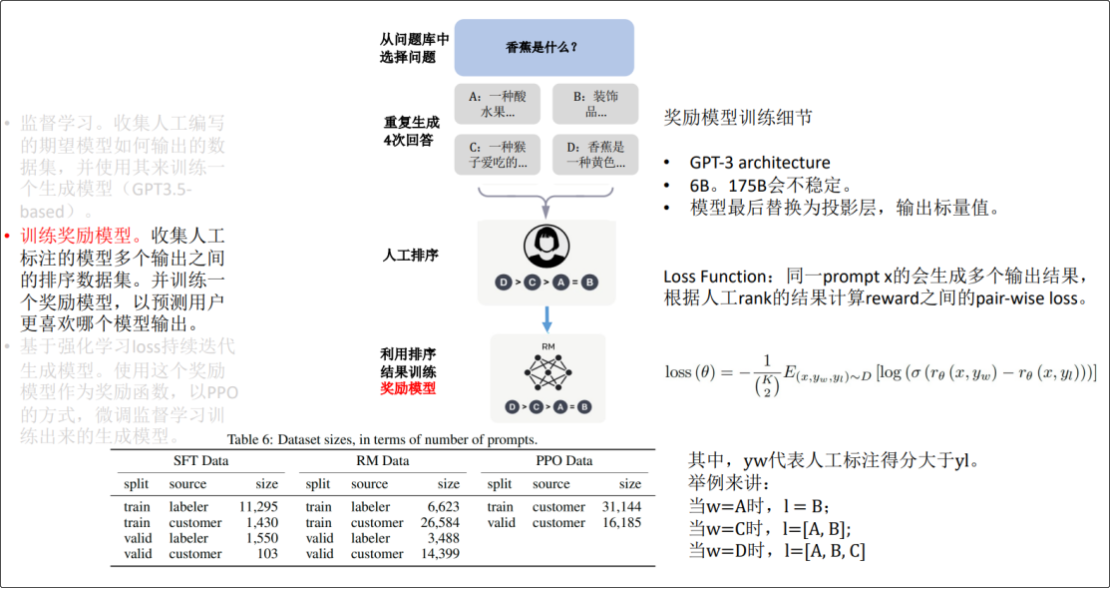 3.基于强化学习 loss 持续迭代生成模型。使用这个奖励模型作为奖励函数,以 PPO 的方式,微调监督学习训练出来的生成模型 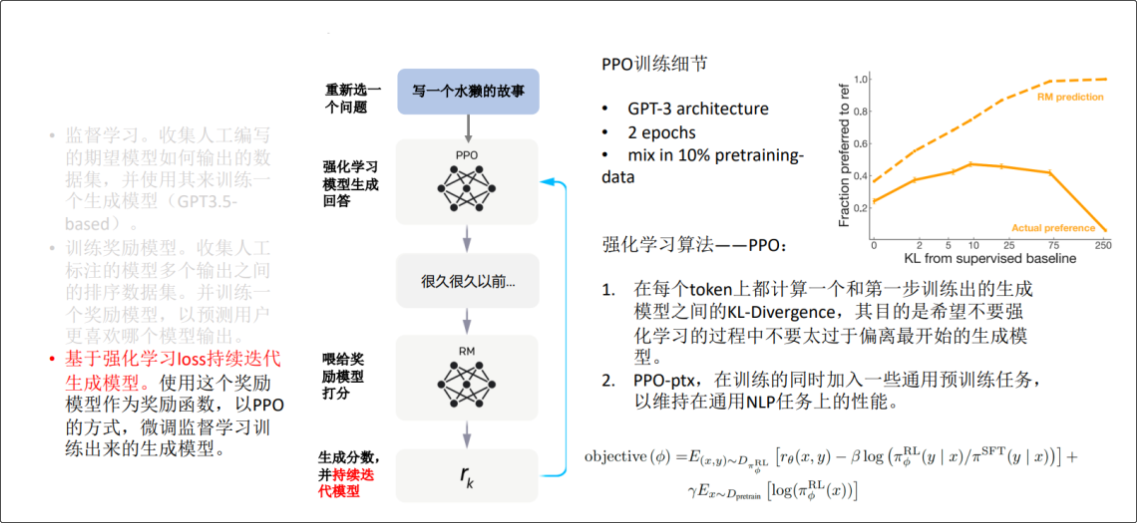 注解:排序任务 
上一篇:
ChatGPT 的前世今生
下一篇:
ChatGPT 的优势
该分类下的相关小册推荐:
生成式AI的崛起:ChatGPT如何重塑商业
人工智能技术基础(下)
AI时代程序员:ChatGPT与程序员(上)
区块链权威指南(下)
巧用ChatGPT做跨境电商
ChatGPT中文教程
深度强化学习--算法原理与金融实践(二)
用ChatGPT轻松玩转机器学习与深度学习
AI-Agent智能应用实战(上)
AI Agent 智能体实战课
AI写作宝典:如何成为AI写作高手
ChatGPT 从 0 到 1











